
Navigation menu
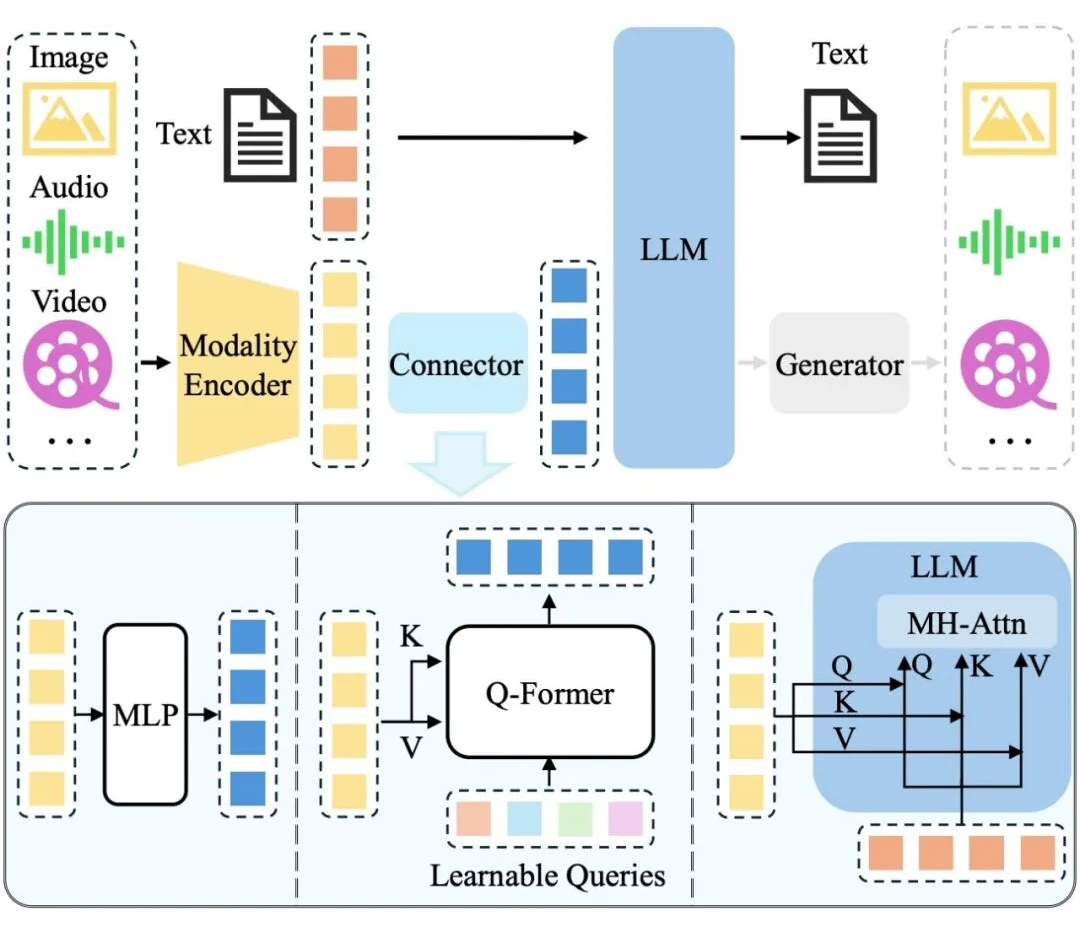 机器中心编辑:熊猫,近年来+0,LLM和多模式扩展(MLLM)继续提高其在各种活动中的认识能力。但是,现有的MLLM主要依靠文本作为表达和构建识别过程的媒介,甚至是处理视觉信息。常见的MLLM结构。此模式要求模型首先“翻译”或“映射”文本或内部文本令牌描述中的视觉信息,然后使用大语言模型的文本推理功能进行处理。这种转换过程可能不可避免地导致视觉信息固有的丰富细节,空间关系和动态特征的丢失或削弱,从而形成了SO被称为“模态差距”。这个空间不仅是视觉世界模型限制了对模型的有效理解,而且还影响了在复杂的视觉情况下有效计划的能力。例如,虽然模型可以区分图像中的对象描述它们之间的一些相对简单的空间关系,在追求准确性的强烈定位或需要对事物之间的极其复杂,动态或隐含的相互作用的深入理解和预测时,它们的性能仍可能会受到限制,从而在发短信的视觉信息中失去细节而受到限制。来自剑桥,伦敦大学和谷歌的研究团队认为,语言并不总是推理的最自然或有效的模式,尤其是在涉及空间和几何信息的工作情况下。基于这一动机,研究团队提出了推理和计划的新范式 - 视觉计划。该范式计划完全基于视觉表示,并且完全独立于文本的方式。纸张标题:视觉计划:让我们考虑一下图片的图片:https://arxiv.org/pdf/2505.11409代码存储库:https://github.com/yix.com/yix8/visualplanning框架,它计划-Enne人们如何通过草图或对象视觉图像计划未来的行为。推理游行的比较。传统方法(上层和中间线)倾向于产生长时间的不准确计划,而视觉范式规划(下线)直接预测了下一步的视觉状态,形成了完全基于图像的状态轨迹,而无需在此过程中使用语言。为了支持这种方法,研究团队建议了创新的增强学习框架 - 通过学习(VPRL)的视觉计划。该轮廓将GRPO(优化小组的相对方法)作为一种核心优化方法,并用于改善训练后大规模视觉模型的计划功能。在视觉导航中的许多典型任务中,包括Frozenlake,Maze和Minibehavior,此方法已取得了重大的性能改进。实验结果表明,如果爱达哈伊ER规划纯文本空间原因的变体,研究团队提出的纯视觉范式在影响方面具有更大的收益。以下是一个动态的例子:冷冻湖:这是一个随机的网格世界环境。代理需要从指定的起点开始,并且可以安全地达到目标位置。在此期间,应避免掉入“冰洞”。迷宫迷宫:代理商获得了一个初始图像,显示迷宫布局。它的任务是从起点(绿色标记)到迷宫,最后到达点的末端(危险信号所在的位置)。 Minibehaviour:代理需要从起点转移到打印机所在的位置并“拾取”它,然后将打印机带到桌子上并“丢弃”。这项研究不仅证明了视觉计划是可行的替代方案,而且还揭示了其在需要轻松理解图像并打开新方向的活动中的巨大潜力用于对图像和推理的理解领域。通常通过在文本字段中映射视觉信息,例如将其转换为诸如对象名称,特征或关系等标签,以及采取多个语言推理的许多步骤,从而解决了由视觉范式计划大多数以前的任务驱动的研究的研究。但是,一旦将视觉内容转换为文本表示,工作就会恶化纯语言推理问题,语言模型可以通过不引入从视觉模态到过程的信息来完成推理。研究团队提出的范式的视觉计划与上述方法基本不同。它是按照纯视觉模式计划的。研究团队正式将视觉计划定义为:给定初始图像v₀,图像t =(ˆv₁,...,ˆvₙ)的中间解释,其中每个ˆvᵢ表示视觉状态并共同形成视觉计划pl一个。具体而言,请注意作为参数生成的视觉模型。视觉计划轨迹以自回归方式形成,每个中间视觉状态ˆVᵢ在初始状态提供的条件下是样本,而先前的开发节目为优化自动回归模型提供了重大好处,并通过连续的奖励信号训练,并表明了长期传记限制的讨论范围。在自回归图像生成的工作中,图像以视觉令牌表示为采用。受RL在语言识别活动中的成功应用的启发,研究团队引入了基于RL的培训框架,以支持大型模型下的视觉计划并采用了GRPO策略。该方法使用视觉状态之间的转换信息来计算奖励,同时证实了一代策略是否符合环境障碍。培训产生有效AXT的策略模型帽子并保持差异 - 在RL阶段的不同探索,研究小组建议创新的两阶段加强学习框架:阶段1:策略初始化。在此阶段,研究团队采用了管理研究,以通过环境中的随机步行形成的轨迹启动视觉生成π_θ模型。目的是在“模拟”环境中产生有效的视觉状态并保持足够的探索。在训练过程中,每个轨迹都由一系列视觉状态组成(v₀,...,vₙ)。对于每个轨迹,研究团队取了N -1个样本图像样本(v≤ᵢ,vᵢ₊₁),其中v≤ᵢ表示前缀-in -the -way前缀(v₀,...,vᵢ)。然后,给定输入的前缀,模型是下一个状态候选的5ANTAD集合{vᵢ₊₁^(j)} _ {j = 1}^k,来自正确的轨迹。候选国家共享相同的前缀。防止模型过度拟合一定的转换并鼓励在开发过程的随机性中,研究团队在训练中随机对候选状态进行随机对管理的候选状态,作为管理的目标,通过最大程度地减少视觉微调功能(VPFT)来优化模型:框架。该图显示了使用自回归大型视觉模型的图像生成中的自动回归大型视觉模型。 GRPO用于训练视觉方法模型,并引入开发奖励,以鼓励推进行动并惩罚非法理由,从而根据目的实现视觉计划。通常,此阶段主要用作加固研究后续阶段的热门开始过程,旨在提高生成图像的计划的相干性和整体质量。第2阶段:视觉计划的研究加强。在第一阶段开始之后,该模型具有强大的勘探能力,这对于研究的研究至关重要,确保该模型涵盖许多状态转移路径并避免属于次优技术。在第二阶段,该模型模仿了未来状态(即潜在行动的后果),并根据生成的结果获得奖励反馈,从而逐渐指导研究有效的视觉计划技术。具体而言,要在输入v≤ᵢ的当前前缀中给出,π_θ^old版的旧版本将采样中间状态的G候选{ˆvᵢ₊₁^(1),...,ˆvᵢ₊₁^(g)}。候选人的每个状态代表仿真的下一个视觉状态,在代理在时间i时采取了一定的动作A^(k)。研究团队使用基于规则的功能基于状态对(Vᵢ,ˆVᵢ₊₁^(k))来分散作用以进行结构化解释。然后,研究小组设计了一个合并的-a -a -reward函数r(vᵢ,ˆvᵢ₊₁^(k))来评分候选人的每个状态,该函数衡量了候选人的状态是否代表有效e在目标状态的进步(即是否有益)。与依赖于研究价值的传统强化研究(评论家)不同,grpo n使用了候选人组中的kaba -Child -Child比较。Criy的主要价值可提供简单的解释和更好的培训信号。此时,每个候选者的相对优势,A^(k)的计算如下:指导模型产生更好的候选响应并增强高级优势行为的倾向,研究团队根据以下目的功能更新了方法:d确定前fepix,ρ^(k)=π_θ(k)=π_θ(k)=πvᵢ₊₁vᵢ₊₁v20(k)采样比的重要性。奖励设计。与文本的离散操作或令牌不同,视觉输出通常是高度稀疏的信息,这很难直接腐烂解释。在研究小组的视觉计划框架下,主要挑战是如何o判断生成的视觉状态是否可以准确表达相应的计划行动。因此,考虑到环境障碍,奖励设计着重于评估目标状态的进步。为了明确解释从Vᵢ状态到候选人状态ˆVᵢ₊ₜ^(k)的状态,研究团队指定了状态-Action -function p:v×v→a∪e,其中一个代表有效的动作,E代表了一组非法的运动状态集(例如身体违规)。该过程可以根据图像分割的独立组件或基于规则的规则来完成,以解释从像素级数据中解释动作的解释。确定动作时,引入了研究小组A“地图开发” d(v)∈ℕ,表明从特定的视觉状态v。=αₒₚₜ到达目标状态所需的剩余步骤或努力的数量,如果它是有效的动作(最佳)R =αₙₒₚₜ,如果它是无动作的动作(非opti)mal)r =αᵢₙᵥ,如果它是实验中的非法作用(不正确),则研究组将αₒₚₜ= 1,αₙₒₚₜ= 0,αᵢₙᵥ= -5设置,从而鼓励了深度的运动和降解。除了提出的VPRL脊柱大纲外,系统变体还完成了对管理方法(与图像相比)的影响(语言)和性能中的优化方法(与增强辅助研究相比进行的微调)的影响的评估,研究团队还提出了一些系统BSOME的一些变体BSOME BSOME BSOME BSOME A BSOME:VISSIAL BSOME a VISSIAL FINSIAL FINSE-FINSUNS PLANIKS PLANIPS(vpft))。研究团队将“通过微调进行视觉计划”(VPFT)作为此框架的简化版本。它的训练结构与第2.2节中的阶段相对应,但使用最佳计划代替随机轨迹。对于每个环境,研究团队是最小步骤的最佳轨迹(v₀^opt,v₁^opt,...,vₙ^opt),轨迹从intiri导向Al状态v₀^opt =v₀至目标状态。在每个步骤中,模型都学会根据当前的前缀V≤ᵢ^OPT来预测下一个状态Vᵢ₊₁^OPT。训练的目的在公式(2)中是相同的,最好的轨迹是给药的信号。基于语言的(SFT)。在这种比较方法中,计划任务是在语言的模式中内置的。与图像开发形式的中间状态不同,该模型需要提出对操作的文本的描述。正式地,给定视觉状态V和文本提示P,该模型被训练为输入动作t =(t₁,...,t_l)的解释,其中每个令牌tᵢ∈V_Text代表动作。该模型的输入是单词和视觉令牌的提示令牌的划分,目标是文本操作的相应点。研究小组使用了自回归模型中常用的管理维修方法来确定预测通过最大程度地减少跨透明损失的作用离子:视觉计划性能如何实验?该团队根据几项代表性的活动审查了新的视觉计划范式的实际表现。具体来说,该团队在基于语言的视觉计划中进行了分配,该团队使用了三个视觉导航环境:Frozenlake,Maze和Minibehabit。所有这些环境都可以以两种模式解决,从而更容易比较两种技术。在模型方面,团队选择了在视觉数据中进行了完全训练的模型 - 在训练过程中,模型未暴露于任何文本数据。具体而言,他们选择了大型LVM-3B视觉模型作为脊柱网络,并使用了VPFT和VPRL技术。同时,文本比较模型包括具有不同设置的QWEN 2.5-VL-Instructura以及Gemini 2.0 Flash(Gemini-1.0-Flash-002)和高级思维模型Gemini 2.5 Pro(Gemini-13-13-Prre-prre-Preview-03-25)。分析指示ORS使用确切的匹配(EM)和开发率(PR)。那么,视觉计划如何执行?视觉计划击败了文本计划,如下表1所示,视觉策划者(VPFT和VPRL)在所有任务中都达到了最高分数,比使用语言推理的所有基线模型要好。在相同的良好管理训练方法下,VPFT平均比确切匹配(EM)的基于SFT的语言高22%以上,并且VPRL具有更大的优势。在发展速率(PR)方面也观察到类似的趋势。这些结果表明,视觉范式规划对视觉活动有明显的好处,因为语言驱动的技术可能无法固定在任务结构中。纯理解模型(如果是大型封闭资源系统或小型开放资源MLLM)。如果您不收取特定任务,则在完成这些计划任务时会遇到困难。尽管高级思维模型Gemini 2.5 Pro,但在更复杂的活动中迷宫和小马,EM和PR约为50%,这表明当前的切割模型仍然很难应对这些挑战,尽管这些活动在人类中很容易理解。对加强的研究可以带来VPRL刺激研究的两个阶段,这些研究带来了最高的总体表现,超过了其他变体。在第二阶段之后,该模型在简单的Frozenlake工作中实现了完美的计划(91.6%EM,93.2%PR),并在迷宫和Minibehavior的活动中保持了强劲的表现。在所有任务中,性能高于20%以上。正如预期的那样,团队学习培训的第一阶段(强制输出格式但没有教授计划行为)接近随机表现(例如,在Frozenlake数据集中获得的11%EM)。策划者使用新建议的奖励方案进行了完整的第二阶段优化后实现了最佳性能。这种增强具有加强O的主要优势Ver SFT:VPRL允许模型自由探索各种动作并从结果中学习,而VPFT则依赖于模仿并倾向于适合训练分布。通过奖励驱动的更新鼓励剥削,VPRL学会了获得潜在的政策和模式,从而实现了强大的绩效。下图显示了视觉比较的实例。随着复杂性的提高,团队发现,研究强化仍可以在研究不同的活动中使用较大网格的不同技术的性能时仍可以保持其优势,这通常更困难。如图5所示,当在冷冻环境中,Gemini 2.5 Pro的EM得分从98.0%下降到38.8%,而网格尺寸从3×3增加到6×6。相反,新建议的视觉策划者不仅在所有网格尺寸中保持较高的精度,而且还保持了更柔软的表现。同样,VPRL的性能也比VPFT更稳定,EM得分剩余973×3网格中的0.6%在6×6网格中仍达到82.4%,表明Na Vprl非常稳定。
机器中心编辑:熊猫,近年来+0,LLM和多模式扩展(MLLM)继续提高其在各种活动中的认识能力。但是,现有的MLLM主要依靠文本作为表达和构建识别过程的媒介,甚至是处理视觉信息。常见的MLLM结构。此模式要求模型首先“翻译”或“映射”文本或内部文本令牌描述中的视觉信息,然后使用大语言模型的文本推理功能进行处理。这种转换过程可能不可避免地导致视觉信息固有的丰富细节,空间关系和动态特征的丢失或削弱,从而形成了SO被称为“模态差距”。这个空间不仅是视觉世界模型限制了对模型的有效理解,而且还影响了在复杂的视觉情况下有效计划的能力。例如,虽然模型可以区分图像中的对象描述它们之间的一些相对简单的空间关系,在追求准确性的强烈定位或需要对事物之间的极其复杂,动态或隐含的相互作用的深入理解和预测时,它们的性能仍可能会受到限制,从而在发短信的视觉信息中失去细节而受到限制。来自剑桥,伦敦大学和谷歌的研究团队认为,语言并不总是推理的最自然或有效的模式,尤其是在涉及空间和几何信息的工作情况下。基于这一动机,研究团队提出了推理和计划的新范式 - 视觉计划。该范式计划完全基于视觉表示,并且完全独立于文本的方式。纸张标题:视觉计划:让我们考虑一下图片的图片:https://arxiv.org/pdf/2505.11409代码存储库:https://github.com/yix.com/yix8/visualplanning框架,它计划-Enne人们如何通过草图或对象视觉图像计划未来的行为。推理游行的比较。传统方法(上层和中间线)倾向于产生长时间的不准确计划,而视觉范式规划(下线)直接预测了下一步的视觉状态,形成了完全基于图像的状态轨迹,而无需在此过程中使用语言。为了支持这种方法,研究团队建议了创新的增强学习框架 - 通过学习(VPRL)的视觉计划。该轮廓将GRPO(优化小组的相对方法)作为一种核心优化方法,并用于改善训练后大规模视觉模型的计划功能。在视觉导航中的许多典型任务中,包括Frozenlake,Maze和Minibehavior,此方法已取得了重大的性能改进。实验结果表明,如果爱达哈伊ER规划纯文本空间原因的变体,研究团队提出的纯视觉范式在影响方面具有更大的收益。以下是一个动态的例子:冷冻湖:这是一个随机的网格世界环境。代理需要从指定的起点开始,并且可以安全地达到目标位置。在此期间,应避免掉入“冰洞”。迷宫迷宫:代理商获得了一个初始图像,显示迷宫布局。它的任务是从起点(绿色标记)到迷宫,最后到达点的末端(危险信号所在的位置)。 Minibehaviour:代理需要从起点转移到打印机所在的位置并“拾取”它,然后将打印机带到桌子上并“丢弃”。这项研究不仅证明了视觉计划是可行的替代方案,而且还揭示了其在需要轻松理解图像并打开新方向的活动中的巨大潜力用于对图像和推理的理解领域。通常通过在文本字段中映射视觉信息,例如将其转换为诸如对象名称,特征或关系等标签,以及采取多个语言推理的许多步骤,从而解决了由视觉范式计划大多数以前的任务驱动的研究的研究。但是,一旦将视觉内容转换为文本表示,工作就会恶化纯语言推理问题,语言模型可以通过不引入从视觉模态到过程的信息来完成推理。研究团队提出的范式的视觉计划与上述方法基本不同。它是按照纯视觉模式计划的。研究团队正式将视觉计划定义为:给定初始图像v₀,图像t =(ˆv₁,...,ˆvₙ)的中间解释,其中每个ˆvᵢ表示视觉状态并共同形成视觉计划pl一个。具体而言,请注意作为参数生成的视觉模型。视觉计划轨迹以自回归方式形成,每个中间视觉状态ˆVᵢ在初始状态提供的条件下是样本,而先前的开发节目为优化自动回归模型提供了重大好处,并通过连续的奖励信号训练,并表明了长期传记限制的讨论范围。在自回归图像生成的工作中,图像以视觉令牌表示为采用。受RL在语言识别活动中的成功应用的启发,研究团队引入了基于RL的培训框架,以支持大型模型下的视觉计划并采用了GRPO策略。该方法使用视觉状态之间的转换信息来计算奖励,同时证实了一代策略是否符合环境障碍。培训产生有效AXT的策略模型帽子并保持差异 - 在RL阶段的不同探索,研究小组建议创新的两阶段加强学习框架:阶段1:策略初始化。在此阶段,研究团队采用了管理研究,以通过环境中的随机步行形成的轨迹启动视觉生成π_θ模型。目的是在“模拟”环境中产生有效的视觉状态并保持足够的探索。在训练过程中,每个轨迹都由一系列视觉状态组成(v₀,...,vₙ)。对于每个轨迹,研究团队取了N -1个样本图像样本(v≤ᵢ,vᵢ₊₁),其中v≤ᵢ表示前缀-in -the -way前缀(v₀,...,vᵢ)。然后,给定输入的前缀,模型是下一个状态候选的5ANTAD集合{vᵢ₊₁^(j)} _ {j = 1}^k,来自正确的轨迹。候选国家共享相同的前缀。防止模型过度拟合一定的转换并鼓励在开发过程的随机性中,研究团队在训练中随机对候选状态进行随机对管理的候选状态,作为管理的目标,通过最大程度地减少视觉微调功能(VPFT)来优化模型:框架。该图显示了使用自回归大型视觉模型的图像生成中的自动回归大型视觉模型。 GRPO用于训练视觉方法模型,并引入开发奖励,以鼓励推进行动并惩罚非法理由,从而根据目的实现视觉计划。通常,此阶段主要用作加固研究后续阶段的热门开始过程,旨在提高生成图像的计划的相干性和整体质量。第2阶段:视觉计划的研究加强。在第一阶段开始之后,该模型具有强大的勘探能力,这对于研究的研究至关重要,确保该模型涵盖许多状态转移路径并避免属于次优技术。在第二阶段,该模型模仿了未来状态(即潜在行动的后果),并根据生成的结果获得奖励反馈,从而逐渐指导研究有效的视觉计划技术。具体而言,要在输入v≤ᵢ的当前前缀中给出,π_θ^old版的旧版本将采样中间状态的G候选{ˆvᵢ₊₁^(1),...,ˆvᵢ₊₁^(g)}。候选人的每个状态代表仿真的下一个视觉状态,在代理在时间i时采取了一定的动作A^(k)。研究团队使用基于规则的功能基于状态对(Vᵢ,ˆVᵢ₊₁^(k))来分散作用以进行结构化解释。然后,研究小组设计了一个合并的-a -a -reward函数r(vᵢ,ˆvᵢ₊₁^(k))来评分候选人的每个状态,该函数衡量了候选人的状态是否代表有效e在目标状态的进步(即是否有益)。与依赖于研究价值的传统强化研究(评论家)不同,grpo n使用了候选人组中的kaba -Child -Child比较。Criy的主要价值可提供简单的解释和更好的培训信号。此时,每个候选者的相对优势,A^(k)的计算如下:指导模型产生更好的候选响应并增强高级优势行为的倾向,研究团队根据以下目的功能更新了方法:d确定前fepix,ρ^(k)=π_θ(k)=π_θ(k)=πvᵢ₊₁vᵢ₊₁v20(k)采样比的重要性。奖励设计。与文本的离散操作或令牌不同,视觉输出通常是高度稀疏的信息,这很难直接腐烂解释。在研究小组的视觉计划框架下,主要挑战是如何o判断生成的视觉状态是否可以准确表达相应的计划行动。因此,考虑到环境障碍,奖励设计着重于评估目标状态的进步。为了明确解释从Vᵢ状态到候选人状态ˆVᵢ₊ₜ^(k)的状态,研究团队指定了状态-Action -function p:v×v→a∪e,其中一个代表有效的动作,E代表了一组非法的运动状态集(例如身体违规)。该过程可以根据图像分割的独立组件或基于规则的规则来完成,以解释从像素级数据中解释动作的解释。确定动作时,引入了研究小组A“地图开发” d(v)∈ℕ,表明从特定的视觉状态v。=αₒₚₜ到达目标状态所需的剩余步骤或努力的数量,如果它是有效的动作(最佳)R =αₙₒₚₜ,如果它是无动作的动作(非opti)mal)r =αᵢₙᵥ,如果它是实验中的非法作用(不正确),则研究组将αₒₚₜ= 1,αₙₒₚₜ= 0,αᵢₙᵥ= -5设置,从而鼓励了深度的运动和降解。除了提出的VPRL脊柱大纲外,系统变体还完成了对管理方法(与图像相比)的影响(语言)和性能中的优化方法(与增强辅助研究相比进行的微调)的影响的评估,研究团队还提出了一些系统BSOME的一些变体BSOME BSOME BSOME BSOME A BSOME:VISSIAL BSOME a VISSIAL FINSIAL FINSE-FINSUNS PLANIKS PLANIPS(vpft))。研究团队将“通过微调进行视觉计划”(VPFT)作为此框架的简化版本。它的训练结构与第2.2节中的阶段相对应,但使用最佳计划代替随机轨迹。对于每个环境,研究团队是最小步骤的最佳轨迹(v₀^opt,v₁^opt,...,vₙ^opt),轨迹从intiri导向Al状态v₀^opt =v₀至目标状态。在每个步骤中,模型都学会根据当前的前缀V≤ᵢ^OPT来预测下一个状态Vᵢ₊₁^OPT。训练的目的在公式(2)中是相同的,最好的轨迹是给药的信号。基于语言的(SFT)。在这种比较方法中,计划任务是在语言的模式中内置的。与图像开发形式的中间状态不同,该模型需要提出对操作的文本的描述。正式地,给定视觉状态V和文本提示P,该模型被训练为输入动作t =(t₁,...,t_l)的解释,其中每个令牌tᵢ∈V_Text代表动作。该模型的输入是单词和视觉令牌的提示令牌的划分,目标是文本操作的相应点。研究小组使用了自回归模型中常用的管理维修方法来确定预测通过最大程度地减少跨透明损失的作用离子:视觉计划性能如何实验?该团队根据几项代表性的活动审查了新的视觉计划范式的实际表现。具体来说,该团队在基于语言的视觉计划中进行了分配,该团队使用了三个视觉导航环境:Frozenlake,Maze和Minibehabit。所有这些环境都可以以两种模式解决,从而更容易比较两种技术。在模型方面,团队选择了在视觉数据中进行了完全训练的模型 - 在训练过程中,模型未暴露于任何文本数据。具体而言,他们选择了大型LVM-3B视觉模型作为脊柱网络,并使用了VPFT和VPRL技术。同时,文本比较模型包括具有不同设置的QWEN 2.5-VL-Instructura以及Gemini 2.0 Flash(Gemini-1.0-Flash-002)和高级思维模型Gemini 2.5 Pro(Gemini-13-13-Prre-prre-Preview-03-25)。分析指示ORS使用确切的匹配(EM)和开发率(PR)。那么,视觉计划如何执行?视觉计划击败了文本计划,如下表1所示,视觉策划者(VPFT和VPRL)在所有任务中都达到了最高分数,比使用语言推理的所有基线模型要好。在相同的良好管理训练方法下,VPFT平均比确切匹配(EM)的基于SFT的语言高22%以上,并且VPRL具有更大的优势。在发展速率(PR)方面也观察到类似的趋势。这些结果表明,视觉范式规划对视觉活动有明显的好处,因为语言驱动的技术可能无法固定在任务结构中。纯理解模型(如果是大型封闭资源系统或小型开放资源MLLM)。如果您不收取特定任务,则在完成这些计划任务时会遇到困难。尽管高级思维模型Gemini 2.5 Pro,但在更复杂的活动中迷宫和小马,EM和PR约为50%,这表明当前的切割模型仍然很难应对这些挑战,尽管这些活动在人类中很容易理解。对加强的研究可以带来VPRL刺激研究的两个阶段,这些研究带来了最高的总体表现,超过了其他变体。在第二阶段之后,该模型在简单的Frozenlake工作中实现了完美的计划(91.6%EM,93.2%PR),并在迷宫和Minibehavior的活动中保持了强劲的表现。在所有任务中,性能高于20%以上。正如预期的那样,团队学习培训的第一阶段(强制输出格式但没有教授计划行为)接近随机表现(例如,在Frozenlake数据集中获得的11%EM)。策划者使用新建议的奖励方案进行了完整的第二阶段优化后实现了最佳性能。这种增强具有加强O的主要优势Ver SFT:VPRL允许模型自由探索各种动作并从结果中学习,而VPFT则依赖于模仿并倾向于适合训练分布。通过奖励驱动的更新鼓励剥削,VPRL学会了获得潜在的政策和模式,从而实现了强大的绩效。下图显示了视觉比较的实例。随着复杂性的提高,团队发现,研究强化仍可以在研究不同的活动中使用较大网格的不同技术的性能时仍可以保持其优势,这通常更困难。如图5所示,当在冷冻环境中,Gemini 2.5 Pro的EM得分从98.0%下降到38.8%,而网格尺寸从3×3增加到6×6。相反,新建议的视觉策划者不仅在所有网格尺寸中保持较高的精度,而且还保持了更柔软的表现。同样,VPRL的性能也比VPFT更稳定,EM得分剩余973×3网格中的0.6%在6×6网格中仍达到82.4%,表明Na Vprl非常稳定。